ETL tool documentation
Overview
etl is a lite command-line tool for extracting, transforming, and loading data from various sources. Inspired by the simplicity of SQLite or DuckDB databases, etl aims to provide a simple, easy-to-use tool for tasks that can be easily set up with just a few commands without the need for complex tools or programming. etl allows users to extract data from a variety of sources, including CSV, JSON, XML, Excel, SQL databases, and Google Sheets. The lightweight nature of etl makes it ideal for small to medium-sized projects, where a more heavyweight etl tool may be overkill. In this documentation, we will cover how to install and use etl, as well as provide examples and best practices.
Installation
Prerequisites
Before installing etl, you will need the following:
Git (https://git-scm.com/)
Python 3.9 or higher (https://www.python.org/downloads/)
Installing with pip
The easiest way to install etl is to use pip, the Python package installer. Simply run the following command in your terminal:
1 $ pip3 install git+https://github.com/ankiano/etl.git
2 $ pip3 install git+https://github.com/ankiano/etl.git -U # update version if exists
3 $ sudo -H pip3 install git+https://github.com/ankiano/etl.git -U # install to system level
This will install the latest version of ETL from the GitHub repository.
Tip
To install python on Windows it is make sence to use Anaconda3 package (https://www.anaconda.com)
Installing additional dialects
etl uses the SQLAlchemy engine to connect to many different sources, and supports additional dialects for connecting to specific databases. Here are some of the SQL databases and sources supported by SQLAlchemy:
Dialect |
Install Command |
|---|---|
PostgreSQL |
|
Oracle |
|
MySQL |
|
MS SQL Server |
|
SQLite |
|
DuckDB |
|
Presto |
|
Hive |
|
Clickhouse |
|
Google sheets connection realised by pygsheets Files (csv, xlsx, parquet, xml) input and output realised by pandas functionality.
Note
Note that some dialects may require additional configuration or to have the appropriate drivers or client installed. Please refer to the SQLAlchemy dialects documentation for more information on configuring dialects.
Usage instructions
etl can be accessed from the terminal or console. You can also create shell or batch files that contain ETL commands, which can then be scheduled to run at specific intervals using tools like cron.
Options list
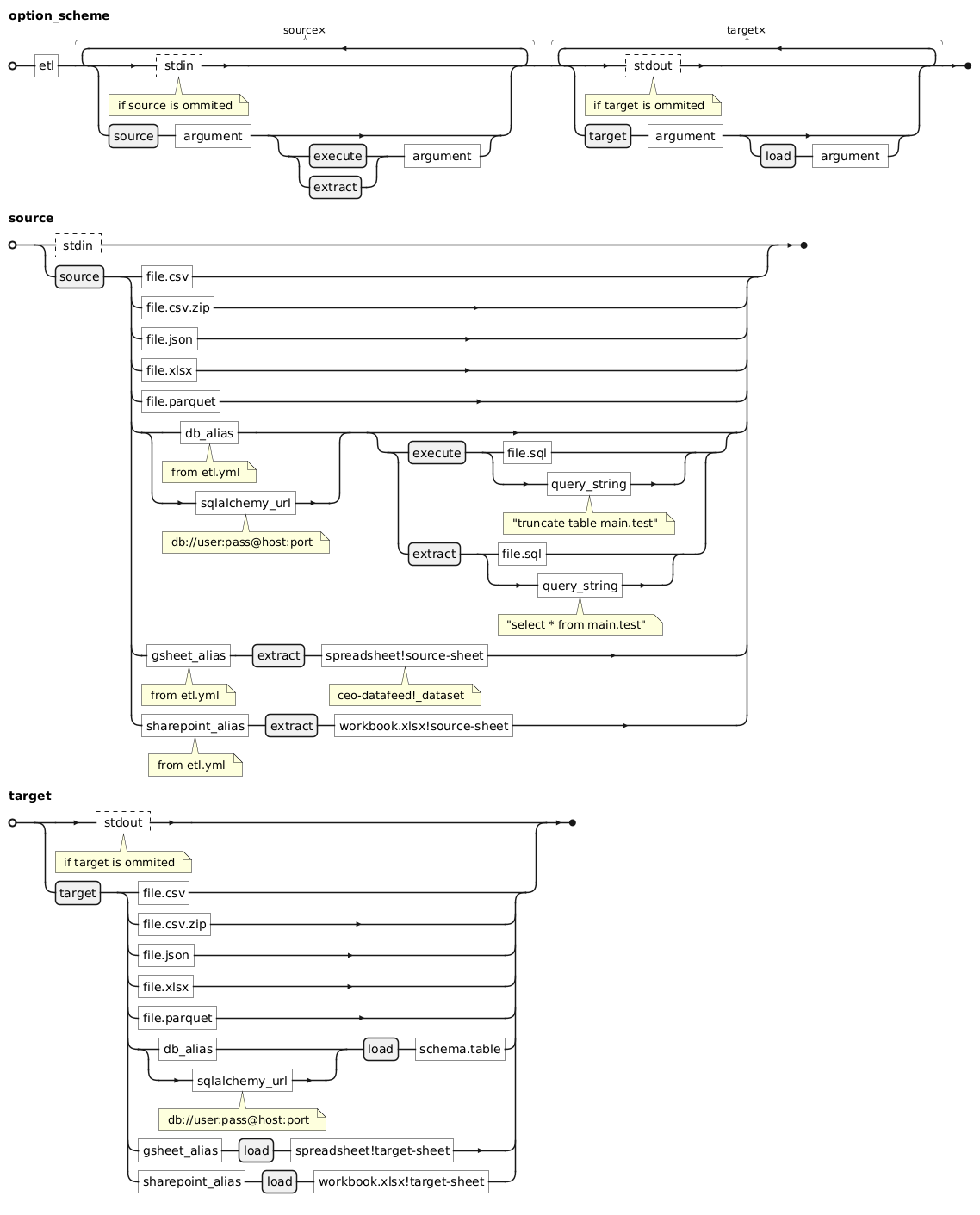
--sourceYou can setup different kinds of sources, such as a filepath, database connection string, or alias from the config file.
--extractAn optional key for databases that allows you to run a query and get the result. You can pass the query as a string, e.g.
select * from table, or as a path to a query file, e.g.sql/query.sql.--executeAn optional key for databases that is used when you need to run a query without returning a result, e.g.
drop table my_table.--targetYou can setup different kinds of targets, such as a filepath, database connection string, or alias from the config file
--loadUsed for loading data to a database to identify which table to load the data into.
--config-pathA custom path to the etl.yml config.
--listList named connections from etl.yml and exit.
--debugEnables an extended level of logging with more information.
--helpProvides short help about the commands.
Quick examples
Open terminal and try to type commands.
1etl --help
2etl --list
3etl --source input.csv --target output.xlsx
4etl --source input.csv --target 'sqlite:///local.db' --load main.my_table
5etl --source db_alias --extract my-query.sql --target result.xlsx
Use cases
These examples show how to use ‘etl’ in a variety of situations. This will help understand how to integrate your project into their own projects.
Shell command files
Usefull to run and repeat etl commands put it in update.sh file. You can build simple pipelines using etl several times and using files or local database for intermidiate result saving.
update.sh1#! /bin/bash 2 3etl --source database_a --extract data-1.sql --target local --load main.data_1 4etl --source database_b --extract data-2.sql --target local --load main.data_2 5 6elt --source local --extract 'select * from data_1 t join data_2 d on t.key=d.key' \ 7 --target result.xlsx
Internet datasets
For data playing perspective it is easy to recive famous dataset from Internet.
update.sh1#! /bin/bash 2 3dataset_file='https://raw.githubusercontent.com/mwaskom/seaborn-data/master/titanic.csv' 4etl --source "$dataset_file??sep=," \ 5 --target input/titanic.xlsx
Report or dashboard update in google sheets
We can build quick report and dashboards using google sheets. You just need create worbook, share this book to technical email in .google-api.key.json and use etl to upload data to needed sheet. If sheet not exists, etl create it automaticaly. If you will load data several times, etl erase each time values from sheet and insert new data.
update.sh1#! /bin/bash 2 3etl --source some_db --extract sql/query.sql \ 4 --target gsheet --load some-gsheet-workbook!my-sheet
Report or dashboard update in sharepoint or onedrive business excel
Also We can build quick report and dashboards using excel. You have to configure .ms-api-key.yml (you can find details in Configurating chapter) Then you can create worbook and use etl to upload data to needed sheet. If sheet not exists, etl create it automaticaly. If you will load data several times, etl erase each time values from sheet and insert new data.
update.sh1#! /bin/bash 2 3#workbook='users/john.do@organization.org/drive/root:/report.xlsx:' #onedrive 4workbook='sites/381b6266-d315-4e73-a947-65742ed52999/drive/root:/report.xlsx:' #sharepoint 5 6etl --source some_db --extract sql/query.sql \ 7 --target sharepoint --load "$workbook??sheet_name=_query"You can setup path to excel file with different notations:
OneDrive Business :
/users/john.do@organizaion.org/drive/root:/Test/Book1.xlsx:Sharepoint Sites:
/sites/{site-id}/drive/root:/Sales/Book2.xlsx:
https://organizaion.sharepoint.com/sites/{site-name}/_api/site/idParameters inside sql query
It is possibility to use parameters inside of sql. In sql you should place parameter in python format
select * from table where param = {user_sql_parameter}And add option key with name of this custom parameter to update query with value.update.sh1#! /bin/bash 2 3etl --source some_db --extract sql/query-template.sql \ 4 --user_sql_parameter 123 \ 5 --target output/result.xlsxParameter values are rendered before the main query, so a query fragment passed as a parameter may also contain parameters.
sql/query-template.sql1with dataset as ( 2 {dataset_query} 3) 4select * from datasetupdate.sh1#! /bin/bash 2 3dataset_query="select * from table where date = '{date_arg}'" 4 5etl --source some_db --extract sql/query-template.sql \ 6 --date_arg 2026-06-01 \ 7 --dataset_query "$dataset_query" \ 8 --target output/result.xlsxParameters use Python format syntax. If the SQL contains literal curly braces, for example in a JSON string, escape them with double braces.
select '{{"a": 1}}' as payload, '{date_arg}' as d
Avoiding limit with google api
Google api has per-minute quotas, request limit of 300 per minute per project. You can extend this limit using several api keys at the same time. You have to setup one alias name but with different keys files. Each time etl runs will select one of them randomly.
This technique can also be used to load balance across identical relational database replica instances.
1gsheet: 'google+sheets://??credentials=~/.google-api-key-1.json'
2gsheet: 'google+sheets://??credentials=~/.google-api-key-2.json'
3gsheet: 'google+sheets://??credentials=~/.google-api-key-3.json'
Loading a set of similar files
Sometimes you have a lot of files to process.
├── input ├── file1.csv ├── file2.csv ├── file3.csv └── file4.csvUsing native bash loop end etl can help you.
1#! /bin/bash
2
3for f in input/file*.csv; do
4 etl --source "$f" --target local --load main.files_content
5done
Best practices
Some example of organizing working directory.
home
└── me
├── playground
│ ├── ad-hoc
| | ├── process-set-of-files
| │ │ ├── input
│ │ │ | ├── file1.csv
│ │ │ | ├── file2.csv
│ │ │ | ├── file3.csv
│ │ │ | └── file4.csv
| | | ├── local.db
| | | ├── update.log
│ │ | └── update.sh
│ ├── report
│ │ ├── demo-dashboard
│ │ │ ├── sql
│ │ │ │ └── data-cube.sql
│ │ │ └── update.sh
│ │ ├── demo-datafeed
│ │ │ ├── sql
│ │ │ │ └── dataset.sql
│ │ │ ├── update.log
│ │ │ └── update.sh
│ │ └── demo-report
│ │ ├── input
│ │ │ └── titanic.xlsx
│ │ ├── sql
│ │ │ ├── data-dd.sql
│ │ │ └── data-mm.sql
│ │ ├── local.db
│ │ ├── update.log
│ │ └── update.sh
│ ├── crontab
│ └── crontab-update.sh
├── .bash_aliases
├── .etl.yml
├── .google-api-key.json
└── .ms-api-key.json
Config files we can store in user directory
Reports and ad-hoc activities we can store in separated way
Sheduling plan crontab for update reports we can store in playground directory
All sql query we can put in sql directory
For each report, dashboard, datafeed we create update.sh with same name
1local: 'duckdb:///local.db' # use this alias when you need local database in project directory
2gsheet: 'google+sheets://??credentials=~/.google-api-key.json' # use this alias to load data to google sheets
3sharepoint: 'microsoft+graph://??credentials=~/.ms-api-key.yml'
4db_alias1: 'sqlite:////home/user/workspace/folder/some.db'
5db_alias2: 'postgres://user:pass@host:port/database'
6db_alias3: 'mysql+pymysql://user:pass@host:port/database?charset=utf8'
7db_alias4: 'oracle+cx_oracle://sys:pass@host:port/database?mode=SYSDBA'
8db_alias5: 'awsathena+rest://aws_access_key_id:aws_secret_access_key@athena.region_name.amazonaws.com:443/schema_name?s3_staging_dir=s3_staging_dir'
9db_alias6: 'clickhouse+http://user:password@host:8443/db?protocol=https'
10db_alias7: 'duckdb:///C:\\Users\\user\\Desktop\\test.duckdb' # windows path style
1 #!/bin/bash
2
3 cd "$(dirname "$0")" # you need this line if you are planning to sheduling it with cron
4
5 elt --source local --extract sql/my-query.sql --target output/result.xlsx
1 # custom alias for run update.sh or other sh with adding logging
2 # just type 'upd' and you see running log, after exectuing you will see update.log
3 upd () {
4 if [[ -z $@ ]]; then
5 sh update.sh |& tee update.log
6 elif [[ $1 =~ '.sh' ]]; then
7 sh $1 |& tee ${1%.sh}.log
8 fi
9 }
1 # Define enviroment variables
2 SHELL=/bin/bash
3 PATH=/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin:/opt/homebrew/bin
4 HOME="/home/me/"
5 ETL_CONFIG=/home/me/.etl.yml
6
7 ###### test job
8 #*/1 * * * * date >./cron.log 2>&1
9 #*/1 * * * * printenv >>./cron.log 2>&1
10 #*/1 * * * * etl --help >>./cron.log 2>&1
11
12 ###### reports
13 # demo-dashboard
14 0 6 * * * ./playground/report/demo-report/update.sh >./playground/report/demo-report/update.log 2>&1
1 #! /bin/bash
2
3 crontab -l > ./crontab~ #backup current crontab
4 crontab ./crontab
Configurating
In order to set up connections to databases, etl uses the connection string format. However, connection strings can be long. To save time, etl can find the connection string by its alias in a .etl.yml config file:
1local: 'sqlite:///local.db'
2db_alias1: 'sqlite:////home/user/workspace/folder/some.db'
3db_alias2: 'postgres://user:pass@host:port/database'
4db_alias3: 'mysql+pymysql://user:pass@host:port/database?charset=utf8'
5db_alias4: 'oracle+cx_oracle://sys:pass@host:port/database?mode=SYSDBA'
6gsheet: 'google+sheets://??credentials=~/.google-api-key.json'
Config .etl.yml searching priorities:
by command option
--config/somepath/.etl.ymlby OS environment variable:
sudo echo "export ETL_CONFIG=~/etl.yml" > /etc/profile.d/etl-config.shby default in user home directory
Note
windows C:\Users\user\
linux \home\user\
mac \Users\user\
To set up connection to microsoft graph api create file.
1resource: "https://graph.microsoft.com/v1.0/"
2scopes: ["https://graph.microsoft.com/.default"]
3client_id: "{Application ID}" #you registered in active direvroty application
4authority: "https://login.microsoftonline.com/{Tenant ID}" #you organization tenant id
5secret_id: "{Secret id}"
6client_credential: "{Value}" #of Secret ID
You have to register application in microsoft azure active directory of your organization. Give permissions on microsoft graph Sites.ReadWrite.All, Files.ReadWrite.All.
Parameters to source/target
When connecting to a database using a connection string, you can specify various parameters that customize the connection.
These parameters are appended to the connection string, separated by a ? character and can be combined with &.
?charset=utf8: Sets the character encoding to UTF-8 for MySQL?mode=SYSDBA: Connects to the database using the SYSDBA system privilege for Oracle?connection_timeout=<seconds>: Specifies the number of seconds to wait for a connection to be established before timing out for Microsoft SQL Server?s3_staging_dir=<s3-staging-dir>: Specifies the Amazon S3 location where query results are stored.?workgroup=<workgroup-name>: Specifies the name of the workgroup to use for the connection.
For additional details on the parameters supported by your database, please refer to the official documentation of the corresponding database.
Parameters to Pandas and Engine
These parameters are appended to the connection string, separated by a ?? character and can be combined with &.
When specifying databases using the --source and --target option keys, you can pass additional parameters to the engine.
For example, ??max_identifier_length=128 extend the maximum length of column names when saving to certain database systems.
- When specifying files using the
--sourceand--targetoption keys, you can pass additional parameters. - to_csv:
??header=same as header=False, to save data without header??sep=;specify the column delimiter when loading or saving CSV files??low_memory=falsedisable the memory usage optimization for reading large files
- to_excel:
??sheet_name=dataspecify the sheet name to use when saving to an Excel file??mode=afile mode to use (write or append)??engine=openpyxlwrite engine to use, ‘openpyxl’ or ‘xlsxwriter’.
- When loading data to databases using the
--loadoption key, you can pass additional parameters. - to_sql:
??chunksize=1000Specify the number of rows in each batch to be written at a time??if_exists=replaceDrop the table before inserting new values??if_exists=append(by default) insert new values to the existing table.??method=multiPass multiple values in a single INSERT clause